

Model information
- Model Approaches:Predictive Model Notebook, Bias & Disparity Dection Engine (BDDE) Notebook
- Circuits Used: CIRCUIT 06 - CLEARWATER, CIRCUIT 11 - MIAMI, CIRCUIT 17 - FT. LAUDERDALE
- Crime Types Used: Drugs, Robbery, Burglary, Drivers Licenses
- List of judges used: Florida Sentencing Details by Judge
Datasets Used
Number of Years in Dataset
Data Science Techniques Applied
Subject Matter Experts Involved
The Use of Judge Name as a Segment in our Predictive and Causal Models
Due to direct feedback from our subject matter experts, the predictive and causal modelling approaches have been run with and without judge information for comparison reasons.
We chose counties with enough judge information for our modelling purposes and noted that many of the judges names we misspelled, shortened or abbreviated. We have applied "fuzzy" search logic, which you can find in this notebook, to group these variations in judges names together.
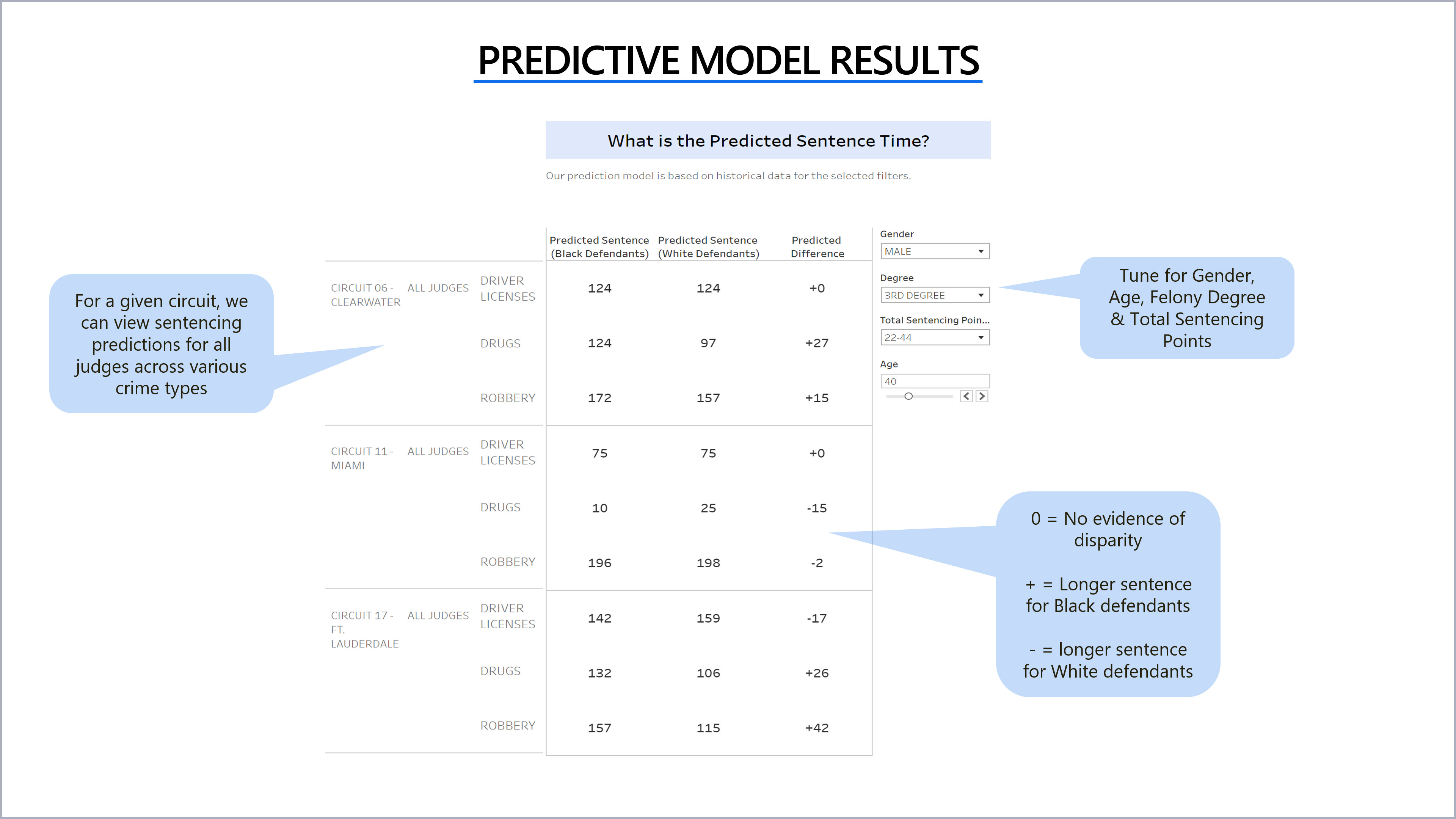
The Use of Segments for the Predictive and Causal Models
To narrow the scope for our MVP we segmented the three circuits and three crime types listed below
- Circuits: CIRCUIT 06 - CLEARWATER, CIRCUIT 11 - MIAMI, CIRCUIT 17 - FT. LAUDERDALE
- Crime Type: Drugs, Robbery and Traffic Control
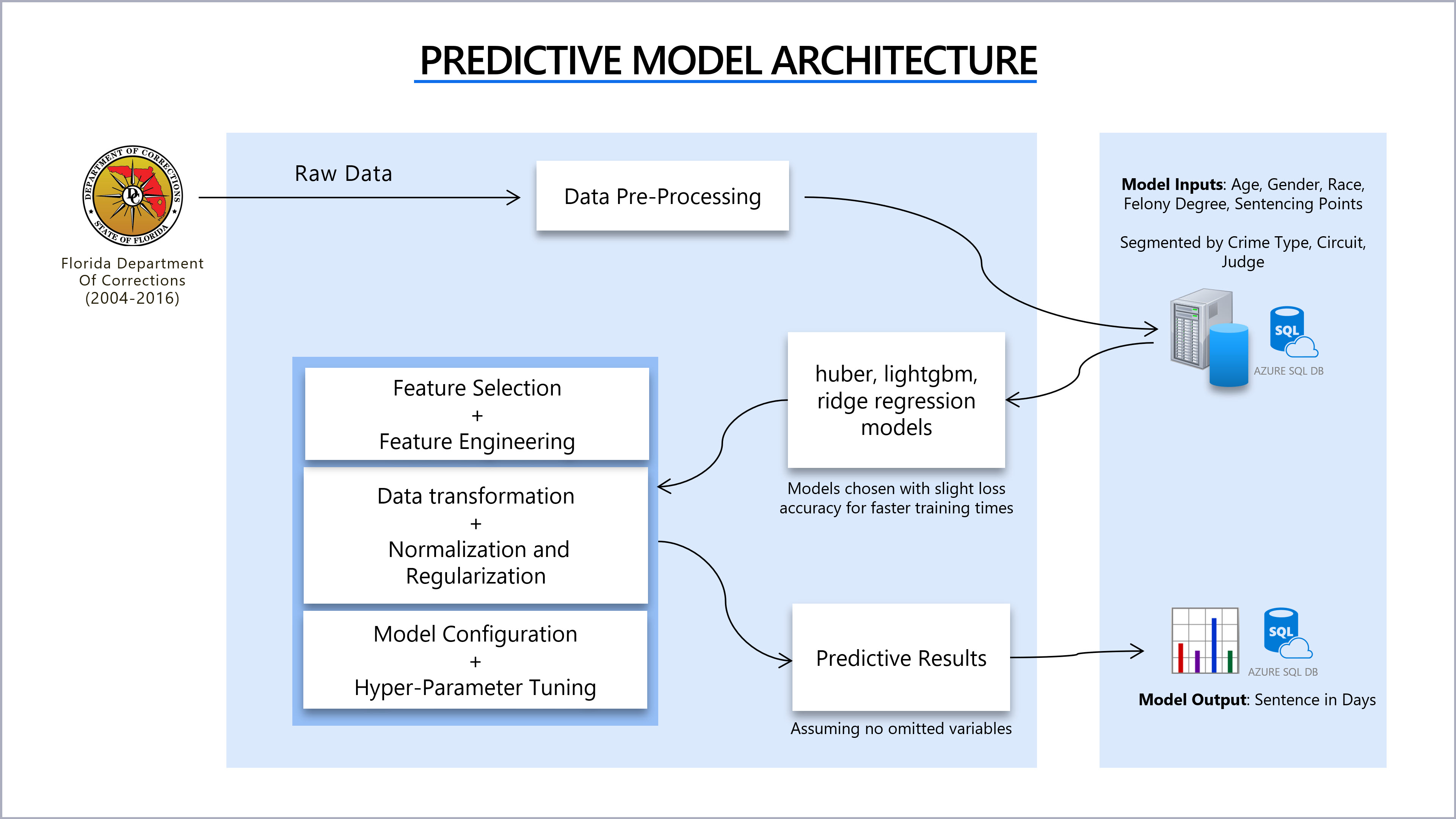
Predictive Modelling:
We leveraged pycaret to evaluate 19 algorithms and of the 19 algorithms, the best models were selected by R2 score. Two sets of predictions on sentencing days were created with and without judge name as a variable.
- Age: 20-86 years of age
- Gender: M/F
- Race: Black/White
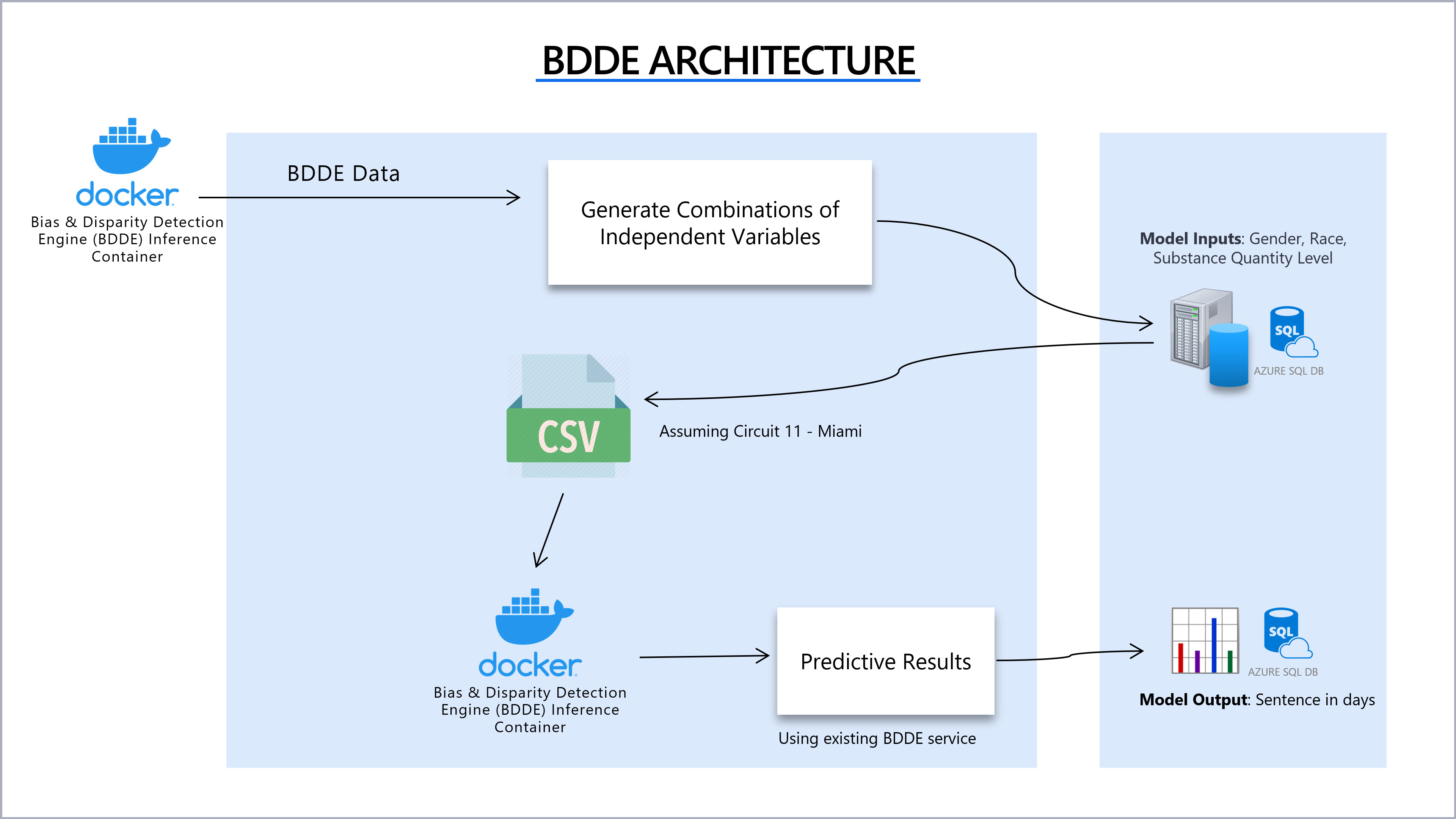
Bias & Disparity Detection Engine (BDDE):
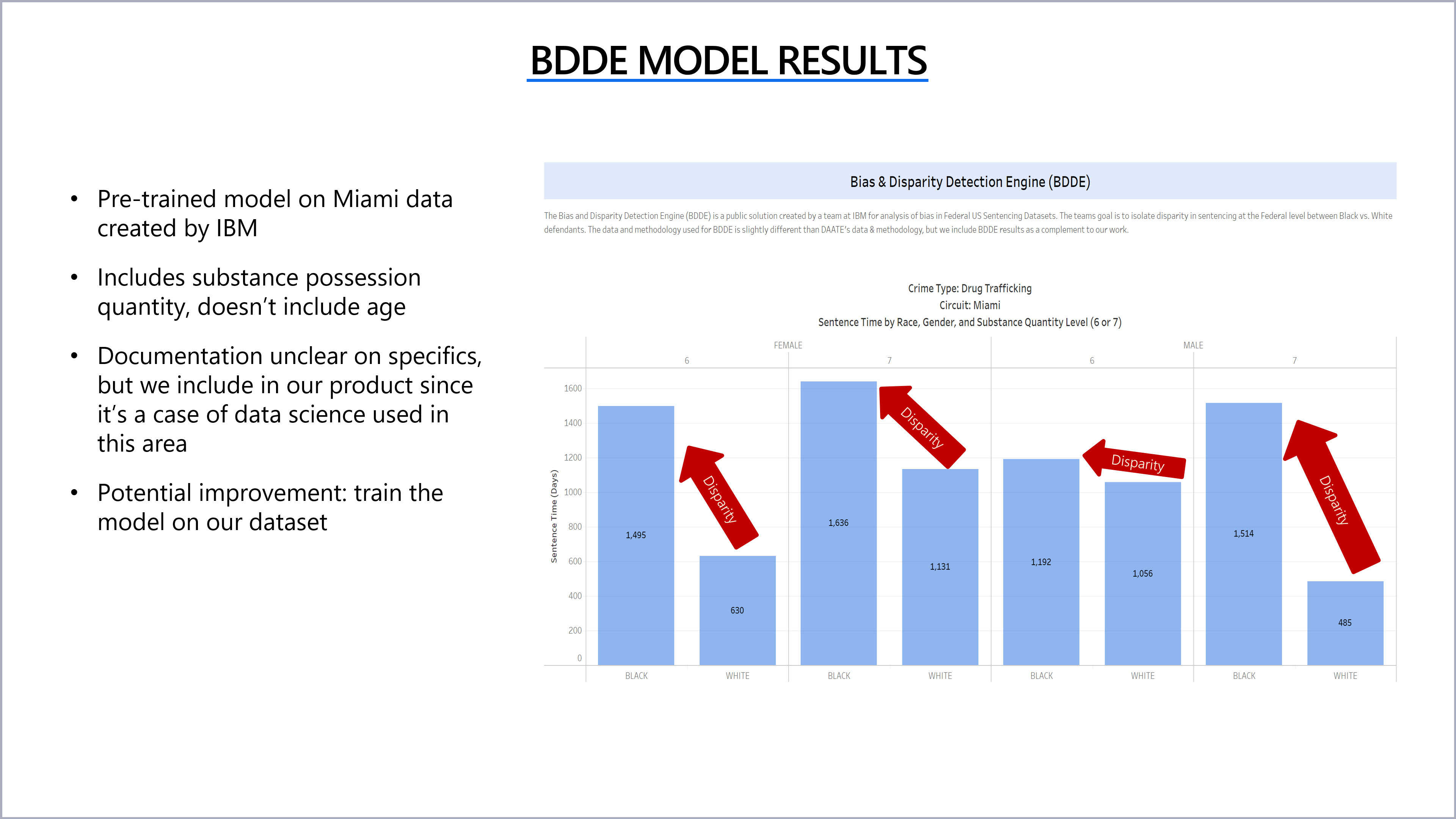
The Bias and Disparity Detection Engine (BDDE) is a public solution created by a team at IBM for analysis of bias and disparity in Federal US Sentencing Datasets. The BDDE teams goal is to isolate disparity in sentencing at the Federal level between Black vs. White defendants. The BDDE team accomplishes this by comparing the average months of sentencing against a historical profile of actual sentences for similar charges by racial demographics.
We include the BDDE approach and results here as a compliment to DAATE and for comparison resaons only.
- Circuit Used: CIRCUIT 11 - MIAMI
- Model Inputs: A CSV was created from the Florida DOC dataset that was sent to the BDDE Inference in the created Docker container. This data includes:
- Crime Type: Drug Trafficking
- Amount: 6,7 (units not specified)
- Gender: M/F
- Race: Black/White
- Model Output:Sentence in days
- Assumptions:
- The data set used be BDDE is Circuit 11 - Miami
- We assumed a level of 6,7 for the amount of possession
- Trade-offs:
- We are using an existing service so no control over functionality
- Challenges:
- Documenation was lacking
- Unclear how to combine these results with our predictive model without "age" as a model input
- Number of sentencing days returned were much larger than expected